 |
|

2 Oggetti VM
Il modo migliore per iniziare a descrivere il sistema di VM di FreeBSD è guardandolo dalla prospettiva di un processo a livello utente. Ogni processo utente vede uno spazio di indirizzamento della VM singolo, privato e contiguo, contenente molti tipi di oggetti di memoria. Questi oggetti hanno varie caratteristiche. Il codice del programma e i dati del programma sono effettivamente un singolo file mappato in memoria (il file binario che è stato eseguito), ma il codice di programma è di sola lettura mentre i dati del programma sono copy-on-write [1]. Il BSS del programma è solamente una zona di memoria allocata e riempita con degli zero su richiesta, detta in inglese “demand zero page fill”. Nello spazio di indirizzamento possono essere mappati anche file arbitrari, che è in effetti il meccanismo con il quale funzionano le librerie condivise. Tali mappature possono richiedere modifiche per rimanere private rispetto al processo che le ha effettuate. La chiamata di sistema fork aggiunge una dimensione completamente nuova al problema della gestione della VM in cima alla complessità già data.
Una pagina di dati di un programma (che è una basilare pagina copy-on-write) illustra questa complessità. Un programma binario contiene una sezione di dati preinizializzati che viene inizialmente mappata direttamente in memoria dal file del programma. Quando un programma viene caricato nello spazio di memoria virtuale di un processo, questa area viene inizialmente copiata e mappata in memoria dal binario del programma stesso, permettendo al sistema della VM di liberare/riusare la pagina in seguito e poi ricaricarla dal binario. Nel momento in cui un processo modifica questi dati, comunque, il sistema della VM deve mantenere una copia privata della pagina per quel processo. Poiché la copia privata è stata modificata, il sistema della VM non può più liberarlo, poiché non ci sarebbe più nessuna possibilità di recuperarlo in seguito.
Noterai immediatamente che quella che in origine era soltanto una semplice mappatura
di un file è diventata qualcosa di più complesso. I dati possono essere
modificati pagina per pagina mentre una mappatura di file coinvolge molte pagine alla
volta. La complessità aumenta ancora quando un processo esegue una fork. Quando un
processo esegue una fork, il risultato sono due processi--ognuno con il proprio spazio di
indirizzamento privato, inclusa ogni modifica fatta dal processo originale prima della
chiamata a fork(). Sarebbe stupido per un sistema di VM
creare una copia completa dei dati al momento della fork()
perché è abbastanza probabile che almeno uno dei due processi avrà
bisogno soltanto di leggere da una certa pagina da quel momento in poi, permettendo di
continuare ad usare la pagina originale. Quella che era una pagina privata viene di nuovo
resa una copy-on-write, poiché ogni processo (padre e figlio) si aspetta che i
propri cambiamenti rimangano privati per loro e non abbiano effetti sugli altri.
FreeBSD gestisce tutto ciò con un modello a strati di oggetti VM. Il file
binario originale del programma risulta come lo strato di Oggetti VM più basso. Un
livello copy-on-write viene messo sopra questo per mantenere quelle pagine che sono state
copiate dal file originale. Se il programma modifica una pagina di dati appartenente al
file originale il sistema dell VM prende un page fault [2] e fa una copia della pagina nel
livello più alto. Quando un processo effettua una fork, vengono aggiunti altri
livelli di Oggetti VM. Tutto questo potrebbe avere un po' più senso con un
semplice esempio. Una fork() è un'operazione comune
per ogni sistema *BSD, dunque questo esempio prenderà in considerazione un
programma che viene avviato ed esegue una fork. Quando il processo viene avviato, il
sistema della VM crea uno starto di oggetti, chiamiamolo A:

A rappresenta il file--le pagine possono essere spostate dentro e fuori dal mezzo fisico del file se necessario. Copiare il file dal disco è sensato per un programma, ma di certo non vogliamo effettuare il page out [3] e sovrascrivere l'eseguibile. Il sistema della VM crea dunque un secondo livello, B, che verrà copiato fisicamente dallo spazio di swap:
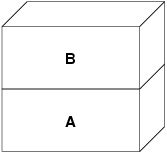
Dopo questo, nella prima scrittura verso una pagina, viene creata una nuova pagina in B, ed il suo contenuto viene inizializzato con i dati di A. Tutte le pagine in B possono essere spostate da e verso un dispositivo di swap. Quando il programma esegue la fork, il sistema della VM crea due nuovi livelli di oggetti--C1 per il padre e C2 per il figlio--che restano sopra a B:
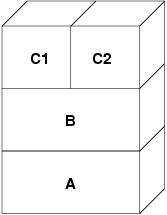
In questo caso, supponiamo che una pagina in B venga modificata dal processo genitore.
Il processo subirà un fault di copy-on-write e duplicherà la pagina in C1,
lasciando la pagina originale in B intatta. Ora, supponiamo che la stessa pagina in B
venga modificata dal processo figlio. Il processo subirà un fault di copy-on-write
e duplicherà la pagina in C2. La pagina originale in B è ora completamente
nascosta poiché sia C1 che C2 hanno una copia e B potrebbe teoricamente essere
distrutta (se non rappresenta un “vero” file). Comunque, questo tipo di
ottimizzazione non è triviale da realizzare perché è di grana molto
fine. FreeBSD non effettua questa ottimizzazione. Ora, supponiamo (come è spesso
il caso) che il processo figlio effettui una exec(). Il suo
attuale spazio di indirizzamento è in genere rimpiazzato da un nuovo spazio di
indirizzamento rappresentante il nuovo file. In questo caso il livello C2 viene
distrutto:
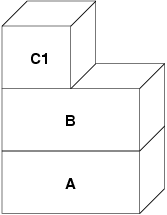
In questo caso, il numero di figli di B scende a uno, e tutti gli accessi a B
avvengono attraverso C1. Ciò significa che B e C1 possono collassare insieme in un
singolo strato. Ogni pagina in B che esista anche in C1 viene cancellata da B durante il
crollo. Dunque, anche se l'ottimizzazione nel passo precedente non era stata effettuata,
possiamo recuperare le pagine morte quando il processo esce o esegue una exec().
Questo modello crea un bel po' di problemi potenziali. Il primo è che ci si potrebbe ritrovare con una pila abbastanza profonda di Oggetti VM incolonnati che costerebbe memoria e tempo per la ricerca quando accadesse un fault. Può verificarsi un ingrandimento della pila quando un processo esegue una fork dopo l'altra (che sia il padre o il figlio). Il secondo problema è che potremmo ritrovarci con pagine morte, inaccessibili nella profondità della pila degli Oggetti VM. Nel nostro ultimo esempio se sia il padre che il figlio modificano la stessa pagina, entrambi hanno una loro copia della pagina e la pagina originale in B non è più accessibile da nessuno. Quella pagina in B può essere liberata.
FreeBSD risolve il problema della profondità dei livelli con un'ottimizzazione speciale detta “All Shadowed Case” (caso dell'oscuramento totale). Questo caso accade se C1 o C2 subiscono sufficienti COW fault (COW è l'acronimo che sta per copy on write) da oscurare completamente tutte le pagine in B. Ponimo che C1 abbia raggiunto questo livello. C1 può ora scavalcare B del tutto, dunque invece di avere C1->B->A e C2->B->A adesso abbiamo C1->A e C2->B->A. ma si noti cos'altro è accaduto--ora B ha solo un riferimento (C2), dunque possiamo far collassare B e C2 insieme. Il risultato finale è che B viene cancellato interamente e abbiamo C1->A e C2->A. Spesso accade che B contenga un grosso numero di pagine e ne' C1 ne' C2 riescano a oscurarlo completamente. Se eseguiamo una nuova fork e creiamo un insieme di livelli D, comunque, è molto più probabile che uno dei livelli D sia eventualmente in grado di oscurare completamente l'insieme di dati più piccolo rappresentato da C1 o C2. La stessa ottimizzazione funzionerà in ogni punto nel grafico ed il risultato di ciò è che anche su una macchina con moltissime fork le pile degli Oggetti VM tendono a non superare una profondità di 4. Ciò è vero sia per il padre che per il figlio ed è vero nel caso sia il padre a eseguire la fork ma anche se è il figlio a eseguire fork in cascata.
Il problema della pagina morta esiste ancora nel caso C1 o C2 non oscurino completamente B. A causa delle altre ottimizzazioni questa eventualità non rappresenta un grosso problema e quindi permettiamo semplicemente alle pagine di essere morte. Se il sistema si trovasse con poca memoria le manderebbe in swap, consumando un po' di swap, ma così è.
Il vantaggio del modello ad Oggetti VM è che fork() è estremamente veloce, poiché non deve aver
luogo nessuna copia di dati effettiva. Lo svantaggio è che è possibile
costruire un meccanismo a livelli di Oggetti VM relativamente complesso che rallenterebbe
la gestione dei page fault, e consumerebbe memoria gestendo le strutture degli Oggetti
VM. Le ottimizazioni realizzate da FreeBSD danno prova di ridurre i problemi abbastanza
da poter essere ignorati, non lasciando nessuno svantaggio reale.
Note
| [1] |
I dati copy on write sono dati che vengono copiati solo al momento della loro effettiva modifica |
| [2] |
Un page fault, o “mancanza di pagina”, corrisponde ad una mancanza di una determinata pagina di memoria a un certo livello, ed alla necessità di copiarla da un livello più lento. Ad esempio se una pagina di memoria è stata spostata dalla memoria fisica allo spazio di swap su disco, e viene richiamata, si genera un page fault e la pagina viene di nuovo copiata in ram. |
| [3] |
La copia dalla memoria al disco, l'opposto del page in, la mappatura in memoria. |
Questo, ed altri documenti, possono essere scaricati da ftp://ftp.FreeBSD.org/pub/FreeBSD/doc/.
Per domande su FreeBSD, leggi la documentazione prima di contattare <questions@FreeBSD.org>.
Per domande su questa documentazione, invia una e-mail a <doc@FreeBSD.org>.